
Reasonable Deprecation Email
Every so often, Google Cloud Platform will send deprecation notices about services they will no longer maintain:
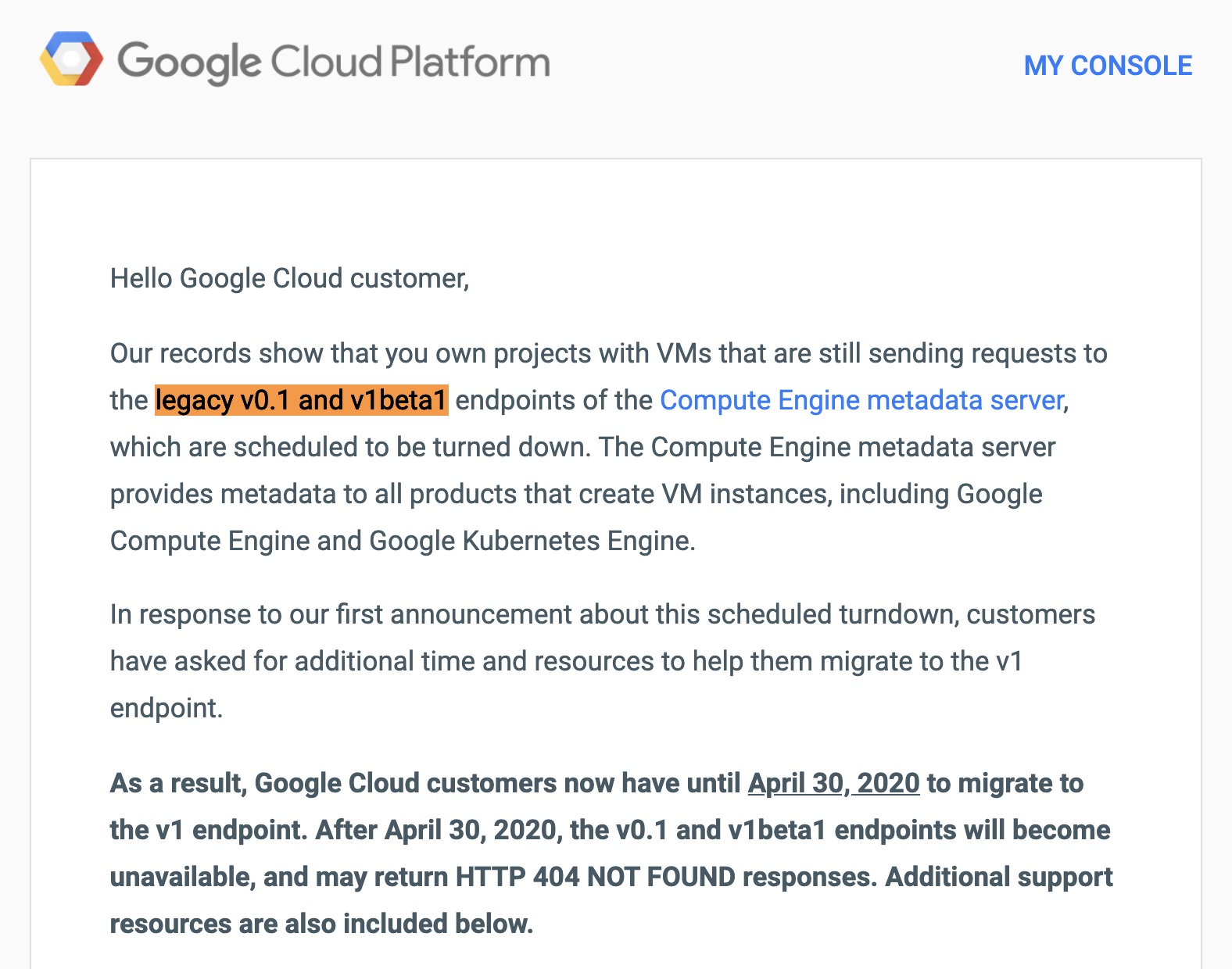
Receiving this email, we weren’t too concerned.
There was a team that looked into each of these deprecation notices, making necessary upgrades.
Looking into this, we couldn’t find anything in our codebase that used these “legacy” “beta” api’s.
Why would we use it? It’s literally called legacy v0.1
May as well call it no seriously don't use this v0.1
So we went on with our lives delivering exceptional value to our customers.
A few months later, the notice is sent again…
…only this time they provide a small list of VM’s using this API.
This is what’s known in the industry as an “Oh shit” moment.
Components of an Oh Shit Moment
- We use a 3rd party Infrastructure-as-a-Service provider to manage our cloud servers.
- That IaaS provider uses some rando custom Ruby lib.
- That library uses this soon-to-be-deprecated legacy API.
- All servers managed by the provider will be deprecated in four months.
All of our servers use this provider.
All of them.
Every single server.
5 months until we lose control of every server in the company.
Oh shit.
Professional Existential Crisis
It’s a hell of a feeling when the scope of work is literally “Everything, Immediately.”
How do you even approach this?
The remainder of this document expresses exactly how to approach the impossible, how to structure a project under duress, and the lessons learned when your technical debt goes to collections.
Break it Down
The first order of business is to ignore the crushing feeling that this is impossible.
It may very well be impossible, but you need to prove it.
We need a wide lens- get a satellite view of the battleground.
We don’t have time to get bogged down focusing on specifics.
Broad strokes across the entire canvas.
The very first thing I did was write down every affected product, every known use case, everything that used the existing server infrastructure.
Itemize the “known knowns.”
It clarifies the work you know you'll have to do
It can reveal the “known unknowns” as well.
With the itemized list, give a super rough time box around how long it would take to fix each one.
5 months turned out to just be this side of possible…
…If we got lucky
…If everything went well,
…If we executed perfectly:
Only the things that didn’t matter too much would slip through.
There were unknown unknowns, and we would have to play jazz when they revealed themselves.
But by writing it all down we had the two most important things needed to make a plan:
- We know our destination.
- We know our starting position.
The delta between your starting position and your destination forms the foundation for your roadmap.
The Good
We did have some things going for us.
By far, the biggest advantage was that 90% of the servers ran a monolithic backend application.
This is actually really good because the monolith shared mostly similar requirements regardless of their use.
Fix it once and you've fixed it for all.
Yes, you are probably correct.
But can you display a birthday on the settings page?
The other thing we had going for us is we actually had enough headcount to have a chance in hell of pulling this off.
We had spent over a year growing and onboarding the team to be sufficiently sized- had we not made this investment, we’d be having a very different conversation.
The Bad
There was no lack of things going against us.
Even putting aside the unreasonable timelines and the sheer scope of work- there were some reaaaal doozies:
We had mission critical servers that didn’t really have owners.
These would be one-off, long-running servers, six years of uptime.
LITERALLY SIX YEARS OF UPTIME.
We don’t really know what these servers do.
Authored by people no longer with the company.
Somehow also mission critical servers.
Not a great look.
The Ugly
While these issues were bad, at least they were within our locus of control.
By far more concerning are the things we had no control over.
Our infrastructure-as-a-service provider wouldn’t help.
At all.
Not even a “good luck.”
In fact, our account rep was on vacation for several weeks, so we couldn't even contact them.
We also get no flex from the GCP side.
Google doth sentenced your execution date, they ain’t gonna change it.
But by far the most ugly thing to deal with was that we were about to make Big Scary Changes™
We were going to parachute into every product team, flip the table and start doing it live.
Product teams would just have to eat it, regardless of their timelines, campaigns, etc.
Which also happened to be a total 180 on how we usually interacted with these teams.
There were going to be some Hard Conversations.
Lessons
- When faced with an impossible task, it’s important to find your grounding.
- Know your destination, know where you’re starting from.
- Put the scope of the problem down on paper
- This lets you feel some form of progress, and allows you to communicate the problem
- Don’t get paralyzed with the impossibility of your task
- Focus on what is possible, what can be done
- Don’t expect help from your vendors
- Especially when you are fully locked-in
The Story Continues
If I had my shit together, this is about the point I’d have a little box getting you to subscribe to my newsletter.
And lock away the remaining articles for paying customers a la Substack.
But I don’t have my shit together, and this story became too long to edit in one sitting, so I’ve busted it out into 3 separate articles.
If you’d be so kind as to click on the next section, seeing the clickthrough on my analytics dashboard would provide me with a hit of dopamine- and that’s the real goal of all of this no?